初探流式计算框架Flink
介绍
Apache Flink 是为分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架。Flink不仅能同时提供支持高吞吐和严格一次(exactly-once)语义的实时计算,还能提供批量数据处理。
Apache Flink 是一个用于对无边界和有边界数据流进行有状态计算的框架和分布式处理引擎。Flink被设计为可在所有常见的集群环境中运行、并能以内存速度和任意规模进行计算。
处理无界和有界数据
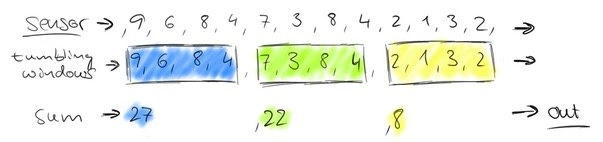
任何类型的数据都是作为事件流产生的,比如信用卡交易、传感器测量、机服务器日志、网站或者移动应用程序的用户交互,所有这些数据均作为流生成。
然后,这些数据,可以作为有界流或者无界流来来处理。
- 无界流有一个起点,但没有确定的终点。它们不会终止并在生成数据时提供数据,无界流必须连续的处理,即,事件在被提取后必须立即处理,无法等待所有输入数据到达再处理,因为输入是无界的,并且在任何时间都不会完成。处理无界数据通常要求以特定的顺序(例如时间发生的顺序)提取事件,以便能够推测出结果的完整性。处理无界流也成为流处理。
- 有界流具有确定的开始和结束。可以通过在执行任何计算之前提取所有数据来处理有界流。由于有界数据始终是可以排序的,因此不需要有序提取即可处理有界流。处理有界流也称为批处理。
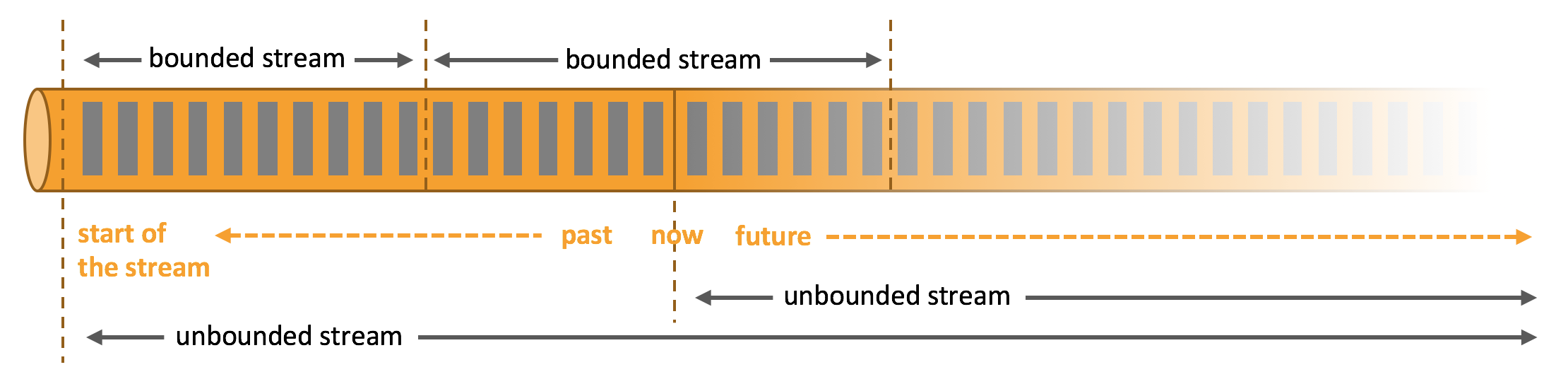
Apache Flink 擅长处理无界和有界数据集。对时间和状态的精确控制使 Flink 的 Runtime 能够在无界流上运行任何类型的应用程序。有界流由专门为固定大小的数据集设计的算法和数据结构在内部进行处理,从而表现出色的性能。
部署方式
Apache Flin k是一个分布式系统,需要计算资源才能执行应用程序。Flink 与所有常见的集群资源管理器(如 Hadoop YARN,Apache Mesos 和 Kubernetes)集成,但也可以设置为作为独立集群运行。
Flink 可以方便的和 Hadoop 生态圈的其他项目集成,例如 Flink 可以读取存储在 HDFS 或 HBASE 中的静态数据,以 Kafka 作为流式的数据源,直接重用 MapReduce 或 Strorm 代码,或通过YARN申请集群资源。
运行规模
Flink旨在运行任何规模的有状态流应用程序。将应用程序尽可能并行化为数千个任务,这些任务在群集中分布并同时执行。因此,应用程序几乎可以利用无限的CPU、主内存、磁盘和网络IO。而且,Flink 易于维护非常大的应用程序状态。它的异步和增量检查点算法可确保对处理延迟的影响降至最低,同时保证 exactly-once 状态一致性。
- 每天处理数万亿事件的应用程序,
- 维护多个TB状态的应用程序,以及
- 运行在数千个内核上的应用程序
利用内存性能
有状态Flink应用程序针对本地状态访问进行了优化。任务状态始终保持在内存中,或者,如果状态大小超出可用内存,则始终保持在访问有效的磁盘数据结构中。因此,任务通过访问通常处于内存中的本地状态执行所有计算,从而产生非常低的处理延迟。Flink通过定期将本地状态异步指向持久性存储来确保出现故障时一次状态的一致性。
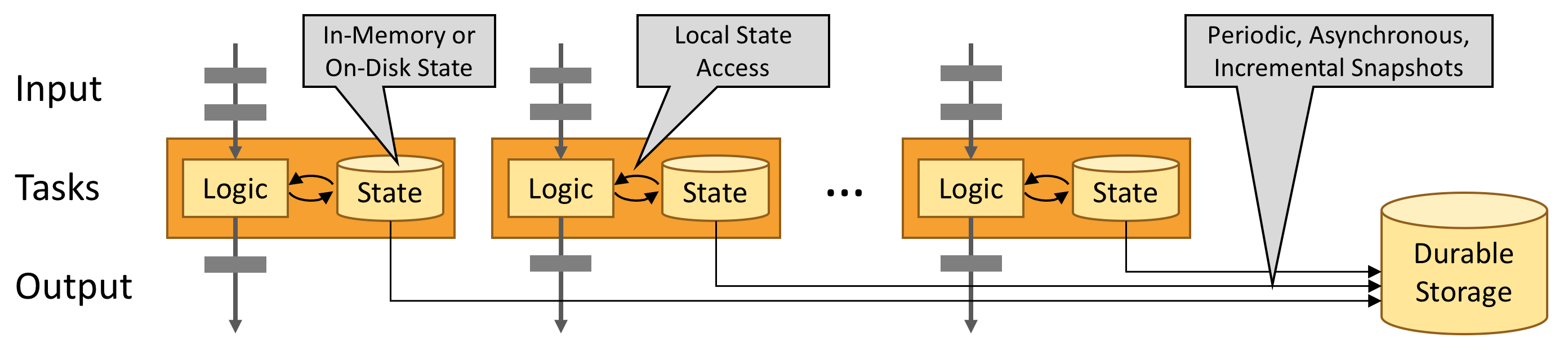
Flink 执行引擎
Flink 的核心计算是 Flink Runtime 执行引擎,它是一个分布式系统,能够接收数据流程序并合并在一台或者多台机器上以容错的方式执行。Flink Runtime 执行引擎可以作为 Hadoop Yarn 的应用程序在集群上运行,也可以在 Apache Mesos 集群上运行,当然最新版也可以在 Kubernetes 上运行,还可以在单机上运行。
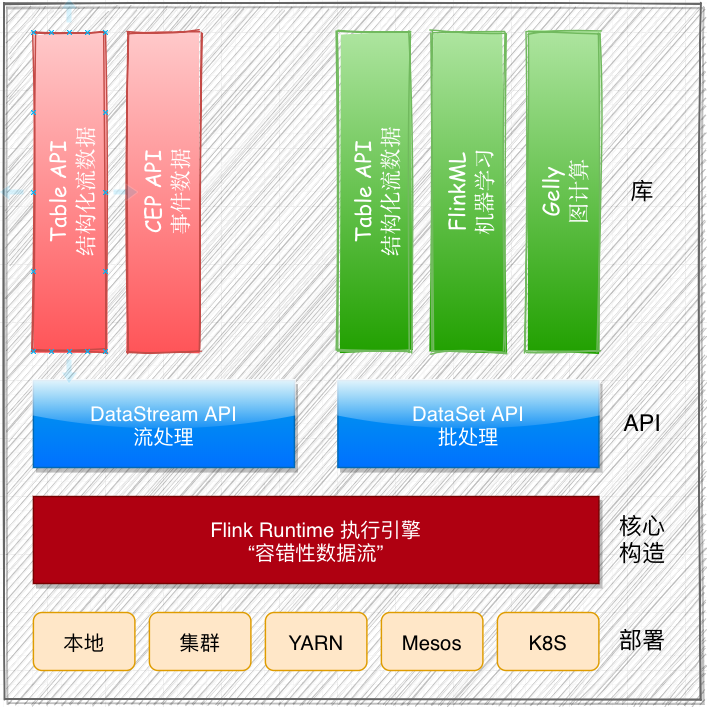
Flink 屏蔽了Runtime 执行引擎的复杂性,提供了封装在 Runtime 执行引擎之上的面向用户的API,以便帮助用户更方便的生成流计算程序。Flink 提供了用于流处理的 DataStream API 和用于批处理的 DataSet API。
尽管 Flink Runtime 执行引擎是基于流处理的,但是 DataSet API 先于 DataStream API 开发出来,因为,在 Flink 诞生初期,业界对无界流计算的需求不大。
DataStream API 可以流畅地分析无限数据流,并且可以用 Java 或者 Scala 来 实现。开发人员需要基于一个 DataStream 的数据结构来开发,这个数据结构用于表示永不停止的分布式数据流。
Flink 解决了许多问题,比如保证了 exactly-once 语义和基于 事件时间的数据窗口。开发人员不再需要在应用层解决相关 问题,这大大地降低了出现 bug 的概率。
- DataSet API: 对静态数据进行处理操作,经静态数据抽象成分布式的数据集,用户可以方便地使用 Flink 提供的各种操作符对分布式数据进行处理,支持 Java、Scala 和 Python。
- DataStream API: 对数据流进行处理操作,将流式的数据抽象为分布式数据流,用户可以方便地对分时数据流进行各种操作,支持 Java 和 Scala。
- Table API: 对结构化数据进行查询操作,将结构化数据抽象成关系表,并通过类 SQL 的 DSL 对关系表进行各种查询操作,支持 Java和 Scala。
- Flink ML: Flink 的机器学习库,提供了机器学习 Pipelines API 并实现了多种机器学习算法。
- Gelly: Flink 的图计算库,提供了图计算相关的 API 以及多种图计算算法实现。
Apache Flink 的架构
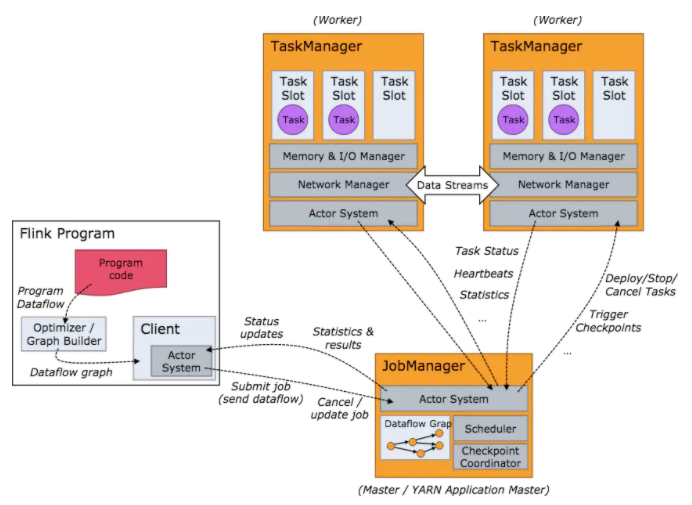
当Flink集群启动后,首先会启动一个 JobManger 和一个或多个的 TaskManager。由 Client 提交任务给 JobManager,JobManager 再调度任务到各个 TaskManager 去执行,然后 TaskManager 将心跳和统计信息汇报给 JobManager。TaskManager 之间以流的形式进行数据的传输。上述三者均为独立的JVM进程。
- Client:提交 Job 的客户端,可以是运行在任何机器上(与 JobManager 环境连通即可)
- JobManager:Flink 系统的协调者,负责任务的排定分配、快照协调、失败恢复控制等,有三种部署方式:单机、一主多备集群、Yarn集群。
- TaskManager:负责具体数据分析任务的执行,主要有业务数据的计算、传输等,相对于 Strom 的 Worker 把内存交给 JVM 管理, Flink 的 TaskManager 还自己管理了部分内存。
- TaskSlot:运行 TaskManager 中固定大小的资源子集,一个 TaskManager 中有多少个 TaskSlot 意味这可以执行多少个 Task。
- Task:执行组件,即业务计算的执行实体。
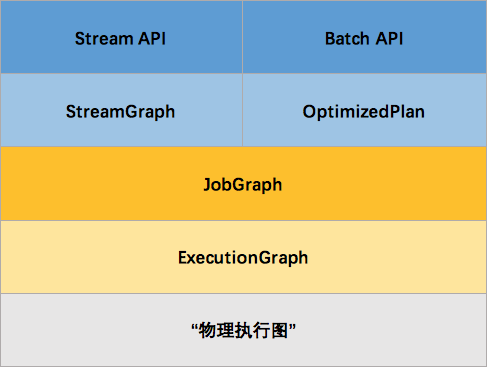
Apache Flink Execution Graph(执行图)
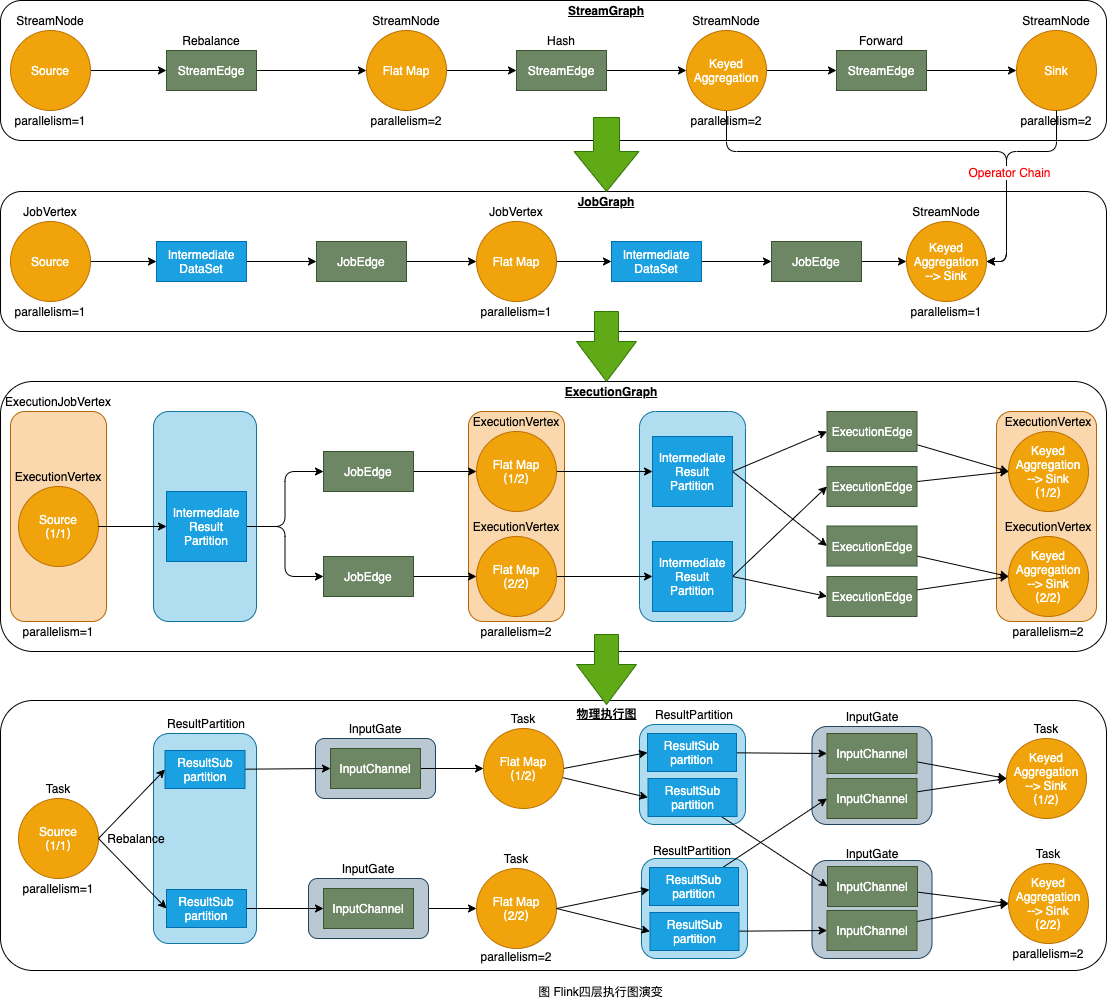
上图为 Flink 四层执行图的演变。Flink 中的执行图可以分为四层:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图,最终的四层执行图如下。
- StreamGraph:是根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。
- JobGraph:StreamGraph 经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点,这样可以节省数据在节点之间的流动所需的序列化/反序列化/传输对资源的消耗。
- ExecutionGraph:JobManager 根据 JobGrap 生成的分布式执行图,是调度层最核心的数据结构。
- 执行物理图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个 TaskManager 上部署 Task 后形成的“图”,并部署一个具体的数据结构。
对Flink四层执行图有了宏观的理解之后,我们细看各个层次中的相关技术名次:
-
StreamGraph:根据用户通过 Stream API 编写的代码生成的最初的图。
-
StreamNode: 用来代表 operator 的类,并具有所有相关的属性,如并发度、inputBound(入界) 和 outputBound(出界)等。
-
StreamEdge: 表示连接两个 StreamNode 的边。
-
JobGraph:StreamGraph经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。
-
JobVertex:经过优化后符合条件的多个StreamNode可能会chain在一起生成一个JobVertex,即一个JobVertex包含一个或多个operator,JobVertex的输入是JobEdge,输出是IntermediateDataSet。
-
IntermediateDataSet:表示JobVertex的输出,即经过 operator 处理产生的数据集。producer 是 JobVertex,consumer 是 JobEdge。
-
JobEdge:代表 Job Graph 中的一条数据传输通道。source 是 IntermediateDataSet,target 是 JobVertex。即数据通过JobEdge由IntermediateDataSet传递给目标JobVertex。
-
ExecutionGraph:JobManager 根据 JobGraph 生成的分布式执行图,是调度层最核心的数据结构。
-
ExecutionJobVertex:和JobGraph中的JobVertex一一对应。每一个ExecutionJobVertex都有和并发度一样多的 ExecutionVertex。
-
ExecutionVertex:表示ExecutionJobVertex的其中一个并发子任务,输入是ExecutionEdge,输出是IntermediateResultPartition。
-
IntermediateResult:和 JobGraph 中的 IntermediateDataSet 一一对应。每一个IntermediateResult的IntermediateResultPartition个数等于该operator的并发度。
-
IntermediateResultPartition:表示ExecutionVertex的一个输出分区,producer是ExecutionVertex,consumer是若干个ExecutionEdge。
-
ExecutionEdge:表示ExecutionVertex的输入,source是IntermediateResultPartition,target是ExecutionVertex。source和target都只能是一个。
-
Execution:是执行一个 ExecutionVertex 的一次尝试。当发生故障或者数据需要重算的情况下 ExecutionVertex 可能会有多个 ExecutionAttemptID。一个 Execution 通过 ExecutionAttemptID 来唯一标识。JM和TM之间关于 task 的部署和 task status 的更新都是通过 ExecutionAttemptID 来确定消息接受者。
-
物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
-
Task:Execution被调度后在分配的 TaskManager 中启动对应的 Task。Task 包裹了具有用户执行逻辑的 operator。
-
ResultPartition:代表由一个Task的生成的数据,和ExecutionGraph中的IntermediateResultPartition一一对应。
-
ResultSubpartition:是ResultPartition的一个子分区。每个ResultPartition包含多个ResultSubpartition,其数目要由下游消费 Task 数和 DistributionPattern 来决定。
-
InputGate:代表Task的输入封装,和JobGraph中 JobEdge 一一对应。每个InputGate消费了一个或多个的ResultPartition。
-
InputChannel:每个InputGate会包含一个以上的InputChannel,和ExecutionGraph中的ExecutionEdge一一对应,也和ResultSubpartition一对一地相连,即一个InputChannel接收一个ResultSubpartition的输出。
 wechat
wechat alipay
alipay