Apache HttpClient调用webflux的服务出现Connection Reset
问题
最近,决策引擎上线了kunpeng-gateway网关,hermod直连kunpeng-gateway的内网域名,存在少量的rst。应用服务端客户端都没有更多的日志信息。

排查经过
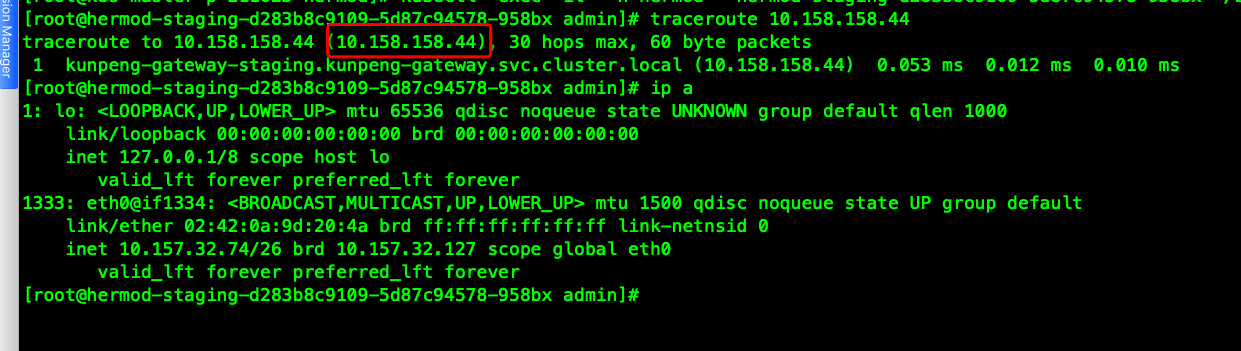
针对该问题,我们内部讨论,首先排查域名使用问题,其次确认集群内容器内访问svc数据包的流向。(kunpeng-gw ip 10.158.158.44)
在我们cni为kube-router的集群上,数据包从容器内出来,直接送到容器所在物理机的kube-dummy-if 网卡。经过本机的ipvs规则(集群外调用svc就很难找到哪个节点的ipvs规则在生效)dnat到目标容器10.157.32.66。



既然起作用的ipvs就是客户端容器所在物理机,这下问题排查起来就容易很多了。除了客户端服务端容器内抓包,我观察客户端所在ipvs规则就可以了。
导入一笔测试流量,在客户端抓包。可以看到tcp三次握手,以及后续push的数据包,并没有收到fin包。客户端到服务端使用了长链接方式。触发一次测试调用后,我收不到任何数据包了就。
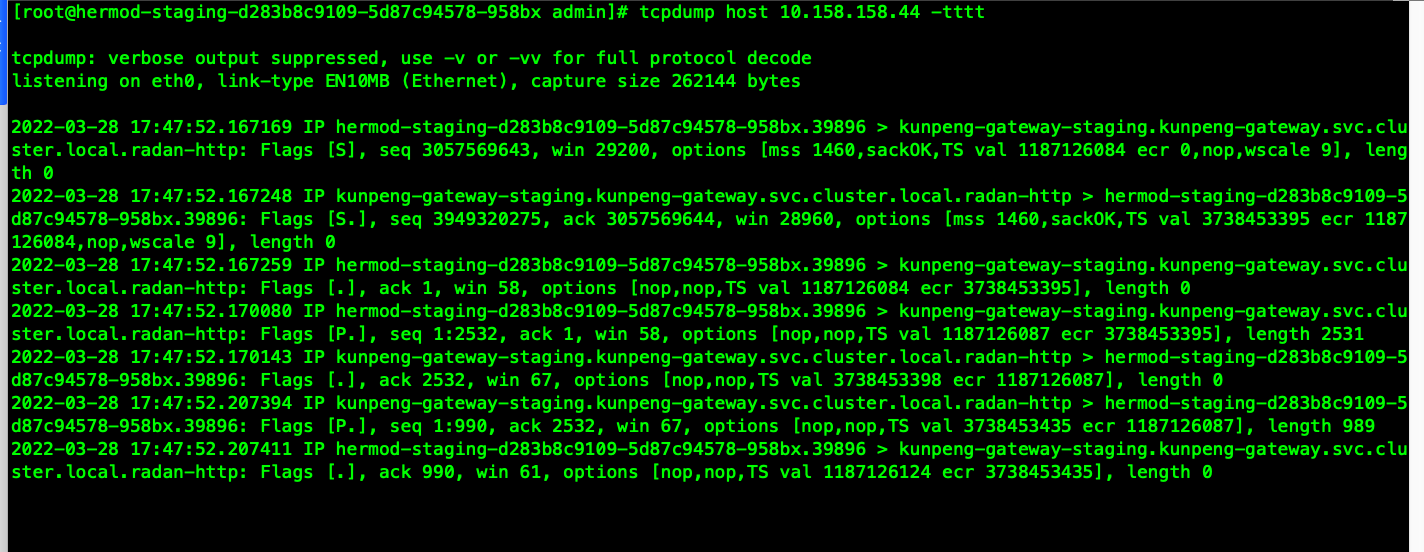
看了下客户端到服务端的链接是存在的。
客户端

服务端

ipvs,其中第二列为过期时间,具体过期时间多少?

看下ipvs会话保持的超时时间。tcp:针对establish的链接的超时时间。tcpfins:客户端发起fin挥手后,FIN_WAIT状态超时时间,udp:udp包超时时间。
系统运维组 > hermod调用kunpeng-gateway域名Connection rest问题 > image2022-3-28 17:51:35.png
conntrack 转发的五元组信息。
系统运维组 > hermod调用kunpeng-gateway域名Connection rest问题 > image2022-3-28 17:55:39.png
系统运维组 > hermod调用kunpeng-gateway域名Connection rest问题 > image2022-3-31 14:21:33.png
起初测试同学帮我在stag环境做了压测,持续压测一段时间后,ipvsadm -lnc 看到的过期时间一直是14:59(超时时间900s换算的倒计时)。观察一段时间,业务日志也没有复现Connection rest现象。
之后我把持续压测的流量停了,ipvs倒计时开始走起来了。
系统运维组 > hermod调用kunpeng-gateway域名Connection rest问题 > image2022-3-29 10:21:56.png
继续观察,期间不再压测。客户端服务端没有数据交互,也没有心跳包。等15分钟倒计时后,ipvs把这个转发的四元组给删了。
再发一笔调用。调用失败。
系统运维组 > hermod调用kunpeng-gateway域名Connection rest问题 > image2022-3-29 10:23:8.png
客户端有rst日志,问题复现。
系统运维组 > hermod调用kunpeng-gateway域名Connection rest问题 > image2022-3-29 10:23:47.png
原因:
系统运维组 > hermod调用kunpeng-gateway域名Connection rest问题 > image2022-3-29 10:39:0.png
如上图,A (hermod)和 B(kunpeng-gateway) 通过NAT 建链,客户端服务端没有流量,同时hermod到kunpeng-gateway之间也没有任何保活机制,当这个时间超过ipvs设置的超时时间15分钟后。
ipvs这个中间人就会把之前建立好的转发规则给删掉了,再之后客户端还使用原先的链路进行push数据被rst了。
下面是出错请求时的报文。
客户端:
系统运维组 > hermod调用kunpeng-gateway域名Connection rest问题 > image2022-3-29 10:34:28.png
由于ipvs的转发链路不存在,服务端没有收到任何报文。
系统运维组 > hermod调用kunpeng-gateway域名Connection rest问题 > image2022-3-29 10:35:16.png
修复:
方案(一)
1.修改内核参数
查阅参考文章了解到tcp保活的几个相关的内核参数。
net.ipv4.tcp_keepalive_intvl、net.ipv4.tcp_keepalive_probes、net.ipv4.tcp_keepalive_time
宿主机:
系统运维组 > hermod调用kunpeng-gateway域名Connection rest问题 > image2022-3-29 10:40:47.png
容器:
系统运维组 > hermod调用kunpeng-gateway域名Connection rest问题 > image2022-3-29 10:42:20.png
容器net namespace有独立的内核参数,不使用k8s-node节点的配置,所以容器内的tcp_keepalive_time为7200s(2小时)。
一旦客户端服务端没有流量,客户端要2小时才能发出第一个心跳包,而ipvs等15分钟就把规则删了。所以这里明显有问题了。
修改容器内的内核参数。(k8s修改内核参数的方式https://kubernetes.io/docs/tasks/administer-cluster/sysctl-cluster/)
这边加个initcontainer赋给root权限,没有直接给业务容器root权限。
initContainers:
- command:
- /bin/sh
- -c
- |
sysctl -w net.ipv4.tcp_keepalive_time=60
sysctl -w net.ipv4.tcp_keepalive_intvl=10
sysctl -w net.ipv4.tcp_keepalive_probes=3
image: registry.hz.td/cd/busybox:latest
imagePullPolicy: Always
name: init-sysctl
resources: {}
securityContext:
privileged: true
继续发一笔流量,长链接建立,倒计时开始,预期的60s到了并没有发现有心跳包发出,还有问题。
修改业务代码:
继续谷歌,参考 https://tldp.org/HOWTO/html_single/TCP-Keepalive-HOWTO/#whyuse 4.2、4.3有C程序关闭和开启了tcp keepalive的例子。对比不难看出来
,业务创建socket时需要开启SO_KEEPALIVE类似的机制,然后才能用得上以上三个内核参数的配置。
在周军文帮助下修改了hermod代码,客户端开启tcp keepalive机制。
系统运维组 > hermod调用kunpeng-gateway域名Connection rest问题 > image2022-3-29 11:12:16.png
客户端服务端建链后,每隔net.ipv4.tcp_keepalive_time时间发送一个心跳包。
系统运维组 > hermod调用kunpeng-gateway域名Connection rest问题 > image2022-3-29 11:19:55.png
至此,再也不会遇到ipvs因为15分钟超时时间而把转发链路删掉的情况了,缺点也看出来了,只要客户端、服务端不主动断链,这条链路几乎不会被释放。
感谢 陈慧同学 提供关于httpclinet 自定义长链接保持时间的设置方法
系统运维组 > hermod调用kunpeng-gateway域名Connection rest问题 > image2022-4-18 15:53:14.png
方案(二)
业务在出现hermod rst的情况后,通过改成原有的使用方式调用forseti-gateway,forseti-gateway再调用kunpeng-gateway来止损,这样用没有rst的情况。
同样的k8s集群,业务也是没有使用,也没法使用4层的保活机制的。因为容器内内核参数的配置导致2小时才有一个心跳包。(后面发现可以通过命令netstat -aptn --timer Time查看是否开启tcp keepalive保活)
当forseti-gateway做为hermod服务端时,持续10分钟左右(我肉眼估计的时间,小于ipvs的超时时间)没有数据交互,服务端forseti-gateway会主动断链。后续hermod再有新的请求,使用重新握手,所以没有rst。
系统运维组 > hermod调用kunpeng-gateway域名Connection rest问题 > image2022-3-29 16:44:55.png
系统运维组 > hermod调用kunpeng-gateway域名Connection rest问题 > image2022-3-29 16:50:56.png
当forseti-gateway做为kunpeng-gateway客户端时,同样forseti-gateway也会主动断链。
得益于forseti-gateway 主动断开没有数据的tcp连接,且断开时间小于ipvs 删除转发规则的时间,所以一直没有出现Connect rest问题。
参考:
 wechat
wechat alipay
alipay