理解Aerospike的基本概念
什么是 Aerospike
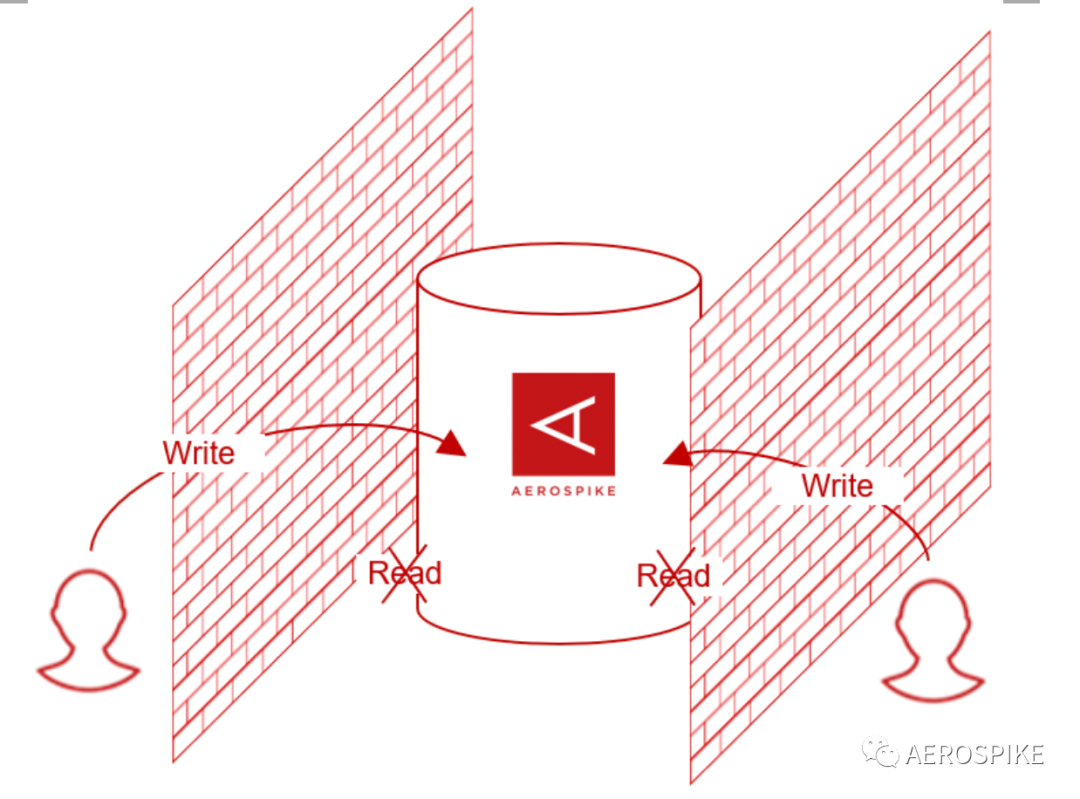
Aerospike(以下简称 AS)一个以分布式为核心基础,可基于 RAM存储索引、数据或将数据存储在闪存/SSD上的是一个分布式数据库。提供类似传统数据库的ACID操作。它主要用于在数百 G、上万 T 的大数据量并且在数万以上并发的情况下,对性能也有毫秒级兑取插入的场景。
目前主要用于互联网广告行业、消息推送行业、直播行业等。
K-V 类型的数据库必须要提的就是 redis,redis 数据完全存储在内存虽然保证了查询性能,但是成本太高。AS 最大的卖点就是可以存储在 SSD 上,并且保证和 redis 相同的查询性能。AS 内部在访问 SSD 屏蔽了文件系统层级,直接访问地址,保证了数据的读取速度。 AS 同时支持二级索引与聚合,支持简单的sql操作,相比于其他 nosql 数据库,有一定优势。
AS 的特性
-
可预见的高性能
99%的响应在 1ms 内实现,99.9%的响应在 5ms 内实现。
-
混合架构
索引存储在 RAM 中,数据存储在闪存或SDD 上。
-
集群感知客户端软件
客户端知晓数据的存放位置,因此能够通过一次单跳就可以检索到数据。
-
无热点
使用复杂的 hash 函数来确保数据均匀分布到所有可用的节点上,从而将请求平均分布到个资源上。
-
数据完整性
保持了高度的一致性,或者允许对跨越多个集群和数据中心的一致性进行调节。
-
线性扩展
能够根据需要安装到多个数据中心内分组为多个集群的多个节点上,添加节点,无需分片,无需人工干预。
-
跨数据中心支持
不同数据中心的集群能够自动协调,从而实现绝对的可靠性。
-
提供主流语言的 API
AS 支持多种主流语言,诸如 C/C++、Java、C#、Python、PHP、Go、Nodejs、Ruby、Perl 等。
基本概念
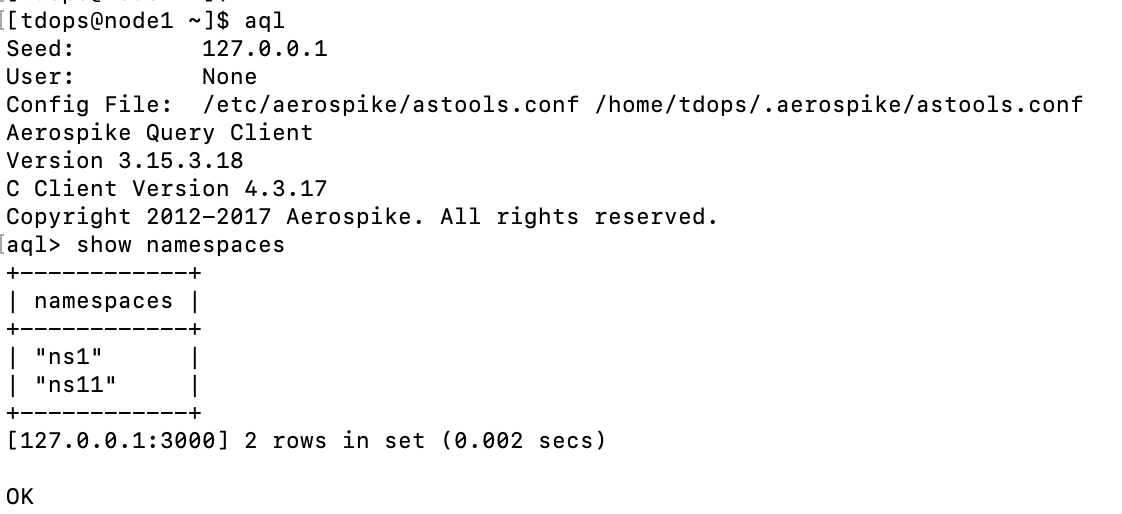
NameSpace
AS数据存储的最高层级,类比于传统的数据库的库层级,一个namespace包含记录(records),索引(indexes )及策略(policies)。
其中策略决定namespace的行为,包括:
-
数据的存储位置是内存还是SSD。
-
一条记录存储的副本个数。
-
过期时间(TTL):不同redis的针对key设置TTL,AS可以在库的层级进行全局设置,并且支持对于已存在的数据进行TTL的设置,方便了使用。
Sets
存储于namespace,是一个逻辑分区,类比于传统数据库的表。set 的存储策略继承自 namespace,也可以为 set 设置单独的存储策略。
Records
类比于传统数据库的行,包含key,Bins(value)和 Metadata(元数据)。key 全局唯一,作为 K-V 数据库一般也是通过key 去查询。Bins 相当于列,存储具体的数据。元数据存储一些基本信息,例如TTL等。
Bins
在一条记录里,数据被存储在一个或多个 bins 里,bins 由名称和值组成。bins 不需要指定数据类型,数据类型有 bins 中的值决定。动态的数据类型提供了很好的灵活性。AS 中每条记录可以由完全不同的 bins 组成。记录无模式,你可以记录的任何生命周期增加或删除 bins 。
在一个库中 bins 的名称最多包含 32k,这是由内部字符串优化所致。(相比于HBase支持几百万列还是有一定差距,如果想直接将 HBase 表迁移到 AS 可能需要重新设计存储结构)。
Key
提到 key,有一个和 key 息息相关的概念是摘要(Digests),当 key 被存入数据库,key 与 set 信息一起被哈希化成一个 160位的摘要。数据库中,摘要为所有操作定位记录。key 主要用于应用程序访问,而摘要主要用于数据库内部查找记录.
Metadata
每一条记录包含以下几条元数据。在 java 客户端,这部分信息融合在 Records 中的,找不到相关 Metadata 的信息。
- generation(代):表示记录被修改的次数。该数字在程序度数据时返回,用来确认正在写入的数据从最后一次读开始未被修改过。
- time-to-live(TTL):AS会自动根据记录的TTL使其过期。每次在对象上执行写操作TTL就会增加。3.10.1版本以上,可以通过设置策略,使更新记录时不刷新TTL。
- last-update-time (LUT):上次更新时间,这是一个数据库内部的元数据,不会返回给客户端。
AS 支持的数据类型
基础类型
-
Integer
- 64 位有符号整数,范围 [$$-2^{63}:\sim:2^{63}-1$$]
- 每个整形占用 8 个字节存储
-
String
- String 是以 NULL- 结尾的 byte 数组,可以达到 128KB
-
Byte
- Byte 数组,可以存储任何二进制数据
复合类型
- List
- 列表集合
- Map
- K-V 键值对集合
- List 和 Map 嵌套
List 和 Map 都可以嵌套,list->list,map->map,list->map,map->list
大数据类型
- Large Ordered List
- 按 key 排序的集合
- 提供的操作有:
- add()/add_all()/update()/update_all()
- find()/exists()
- scan()/filter()
- range()
- remove()/remove_all()/remove_range()
- size()
UDF函数
- 仅支持用 LUA 写,在 server 端执行
- Record UDF: 单记录操作
- Stream UDF: 对分布式集群上的数据进行过滤、转换、汇总
Sencondary Index 和汇总
Sencondary index
- 支持 String/Index 类型
- 支持等于以及范围过滤
- 每个 namespace 最多支持 256 个Sencondary indexes
汇总
通过 lua 的类 MapReduce 实现。
 wechat
wechat alipay
alipay